Consider how a single attention head within a single transformer block of a LLM acts on token at sequence position . The query projection matrix mints a query token where is the head dimension, while the key matrix mints key tokens . The attention compares the token position with all positions via the dot products We absorbe the into the query. The motivation for using dot product originates in the concept of cosine similarity between pairs of vectors , that . In some sense tha pair of tokens are considered similar if the angle between the query of one and the key of the other is small. The attention then computes the softmax on these dots products, which is proportional to , so that the score between relevant token vector are dramatically increased (compared to the dot product) while the score between unreleated token vectors (dot product closer to ) are dramatically diminished by the exponential. These scores are then used to weight the corresponding value vectors to obtain the linear combination Since the sum is commutative, then the attention behaves the same way under permutations of the tokens which is problematic when it comes to modelling language sequences. One particular problem stems from the observation that the further apart two tokens with in a sequence, the weaker they are related: intuiively, tokens within the same sentence are more closely related than words between two paragraphs. Relative position embedding (RoPE) attempts to bake separation distance between two tokens when computing the sum, in particular, RoPE incorporates the distance in the dot product between query and key vectors.
For simplicity let's assume , and let . For every sequence position , rotate each token vector (query and key) by . Thus, after rotation, the angle separating two sucessive token vectors is increased by . The angle separting token vector and token vector is increased by . This scheme incorporates position information as follows: given query and key vectors and with unit norm, even if so that but if occurs at token position and occurs at position , then after rotationing by to obtain and by to obtain then When it is the case that the larger , the smaller the dot product, and therefore the less one token attends to the other. However we can see that if then even though the language model treats it as if . Let maximum context length be , then , so to avoid treating identical tokens that are far apart the same way as if they are at the same token position, we want an angle such that . In particular we can choose Suppose that and we consider we rotate each of the subspaces of token at position by for . Thus we have the action of the -torus on . This map is a linear isometry and is given by a block diagonal matrix where the blocks are 2D rotation matrices. If with lies on the unit circle and and are located at sequence positions and then From it can be see that the wavelength of is which means has a wavelength that is the lower common (positive integer) multiple of the wavelengths we require the context length .
If , and is a random vector on the unit sphere, then since the map is an isometry. In fact due to symmetry under a change of variable . The interpretation of this result is that for any query at any sequence position, the position embedding map is such that the attention score with a key vector chosen uniformly at random at any position is zero in expectation.
Since are identical tokens separated by along the sequence, we desire that in expectation, the attention score of and is greater than the attention score or and a vector chosen uniformly at random from the unit sphere, equivalently As the dot product is continuous, then there exists such that for all tokens semantically close to , in the sense that we have Let us investigate how to have This boils down to asking how to choose the angles so that for all one has
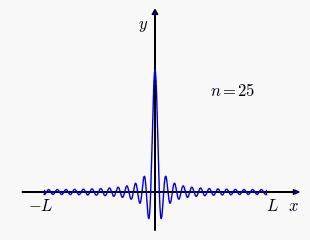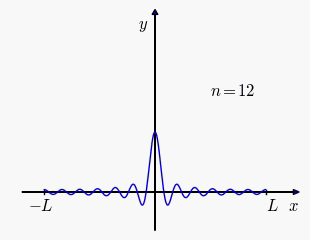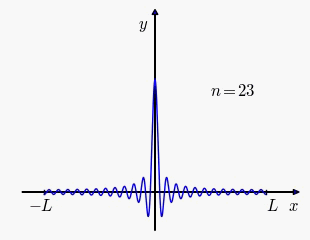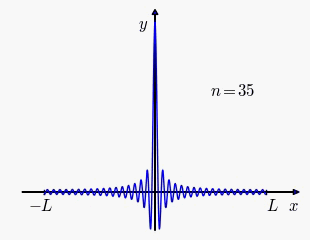
Our first idea is to consider what happens when we choose as an arithemtic progression. We'll overload some notations. After absorbing the common difference into this this boils down to This sum is related to the Dirichlet kernel so
Click to enlarge
Attention score between a pair of identical tokens at different sequence positions when RoPE angles follow arithmetic progression. The oscillation violates so angles that are evenly spaced as an arithmetic progression is unsatisfactory. The second idea is to choose angles in geometric progression: let and for in which case Consider the following integral where we make the substitution where is the cosine integral The first equation is used to simplify above, the second equivalent definition is used by Scipy for plotting.
Click to enlarge
Cosine integral By inspection of the graph of if then when . Let consider choosing in which case
Click to enlarge
Finding a suitable value for b. Observe that suffices to make within a context length . For GPT-OSS this value is . Now we've used . Let's plot the sum
Click to enlarge
Attention strength as sum and its integral approximation (b = 10,000)