Engram and LLM Memory
Feb 23
Engram is a newly proposed memory module for foundation models characterized in a recent DeepSeek paper. The basic idea is to replace on-the-fly knowledge recomputation during forward pass by efficient knowledge lookup. In some sense engram is a new paradigm of neural network sparsity in addition to mixture of experts.
A central problem explored by the engram proposal, which leads to a new scaling law is this: under constant model parameter count, how should sparsely activated parameters be divided amongst engram memory and MoE experts?
Architectural Description
The engram conditional memory module performs the two operations of retrieval and fusion for every token position in a token sequence.
Roughly speaking, the retrieval operator associates sequence local context with static memory entries through a deterministic hash function. Let us enter into a precise description of the steps.
Each word token is associated with an integer called its token ID, this is just recalling standard byte pair encoding (BPE) tokenization. Now we want to further merge sematically similar (normalized textual equivalence, lowercasing) tokens to achieve compression. With being the BPE vocabulary and being the compressed vocabular, the tokenizer compression is simply a map . Every token is first re-tokenized For each and consider the -grams which we hash some times via the mappings The use of multiple hash maps is to prevent hash collision. In implementation, each is a multiplicative XOR hash. The is an index to a memory lookup table from which we retrieve embedding vectors Such vectors are then concatenated (denoted by ) to give a memory embedding vector associated with token
This is the retrieval stage, the other fusion stage invovles so called context aware gating. The operation performed is as follows. Analogous to the QKV matrices, we project the memory embedding for each token position (we will now omit the index and write and likewise is the hidden embedding for token while agreeing that the operation is performed per token) through linear layers and and get We then compute where is the usual root mean square normalizatio layer, is the dimension of the vectors and , and is the sigmoid. The gating is simply the scalar vector product Let be the matrix whose rows are the token gated values , the following operation involves 1D convolution with kernel size and dilation where . This is followed by residual connection, namesly, if we denote the matrix of hidden embeddings (its -th row is ) that is inputted to the engram layer, then output of the engram layer is .
The engram paper uses residual streams, each called a branch. At each engram layer, and for each token, there are multiple hidden vectors , each corresponding to a branch. The above operations are repeated for each hidden vector with the condition that the memory embedding tables and the matrix are shared across all branches, whereas the matrices used for computing is distinct across branches. The architecture also uses manifold constrained hyper connections, which we will discuss in a separate blog.
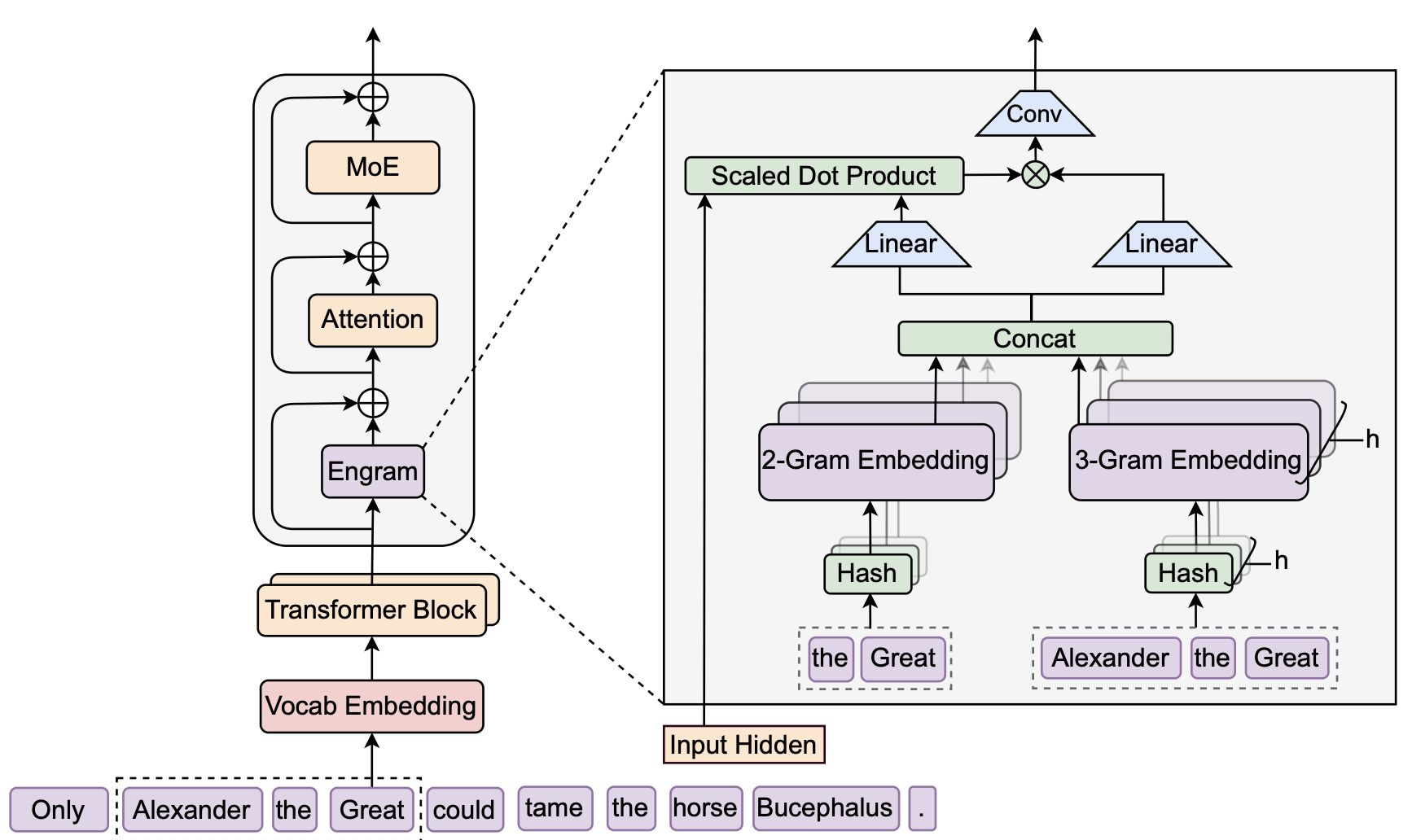
Click to enlarge
Scaling Laws for Memory
In an engram model the number of inactive parameters (per token) is divided between the inactive engram parameters and the inactive MoE expert parameters. Define the ratio In experiments two compute regimes were explored, with as many total parameters as activated parameters per token. First floating point operations, with constant total parameter billion parameters, and constant of million activated parameters per token. The pure MoE model corresponding the case consists of experts. The second compute regime has a fixed compute FLOPs, with fixed and in the pure MoE case there are experts.
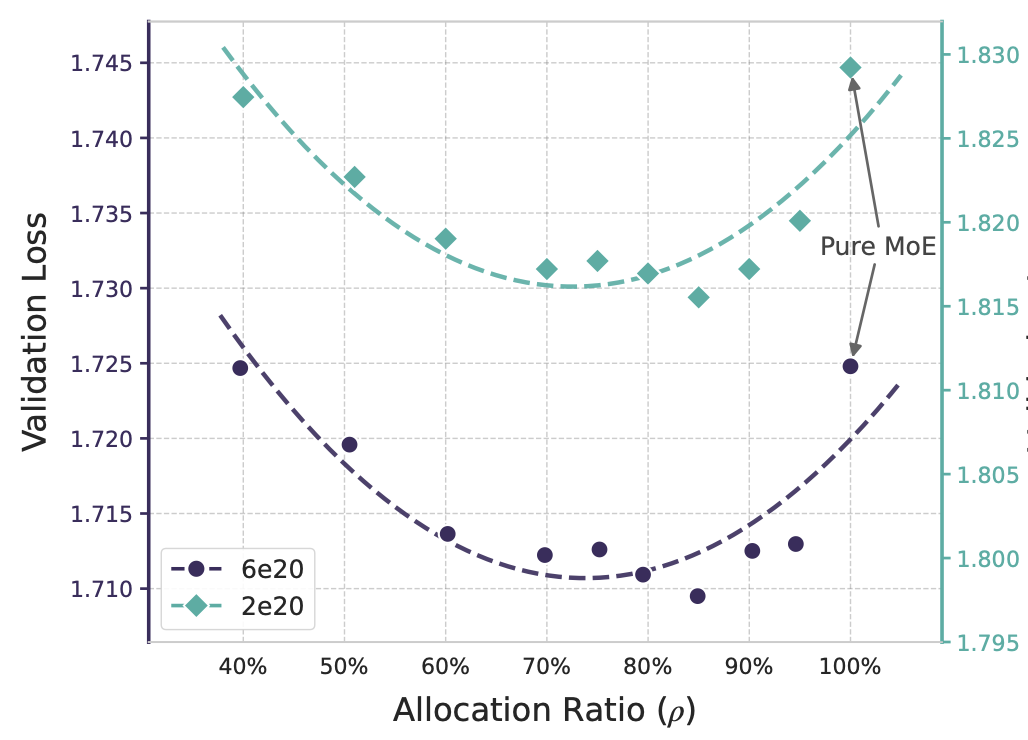
Click to enlarge
Another set of experiments scaled up the number of memory slots over two order magnitudes from to , with a model with activated parameters trained on tokens. The result follows a power law closely.
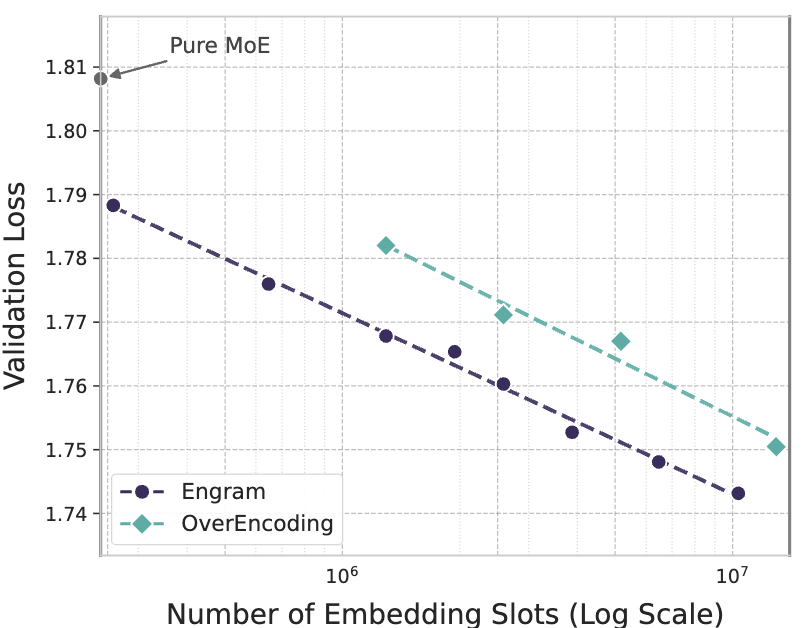
Click to enlarge
Xue J. Zhao © 2026